Dərin öyrənmənin dərin izahı
Mündəricat
1. Giriş
2. Həllində maşın öyrənməsi istifadə olunan məsələlərdən birinin – sinifləşdirmə məsələsinin qoyuluşu
3. Dərin öyrənməyə gətirib-çıxaran inkişaf yolu
4. Süni neyron şəbəkə (ing. Artificial Neural Network, ANN)
4.1. Süni neyron və Perseptron
4.2. Aktivasiya funksiyaları
4.3. Çoxlaylı ANN-lərin öyrədilməsi
5. Dərin neyron şəbəkə (ing. Convolutional Neural Network, CNN)
5.1. “Convolution” və “puling” əməliyyatları
5.2. CNN arxitekturaları və onların növləri
5.3. Təsvirlərin sinifləşdirilməsi üçün istifadə olunan bəzi CNN arxitekturaları
6. İllustrativ nümunə (kodlar və nəticələrlə)
7. Son qeydlər
8. İstinadlar
1. Giriş
Adətən, elmi ədəbiyyatlarda, bloqlarda, o cümlədən ali məktəblərin tədris materiallarında və dərsliklərdə dərin öyrənmənin (ing. deep learning) mahiyyətini, necə işlədiyini, haradan çıxdığını uzun-uzadı izah etmək əvəzinə, dərin öyrənmənin maşın öyrənməsinin bir növü olduğunu qeyd edib üstünlüklərini sadalamaqla kifayətlənirlər. Bu isə dərin öyrənmənin nə olduğunun anlaşılması, dərin öyrənən CNN modellərinin (Convolutional Neural Network, az. bükülmə neyron şəbəkə) işləmə prinsipinin başa düşülməsinə mane olur/kömək eləmir, CNN istifadəçisi olan data scientistlər və elmi tədqiqatla məşğul olanlar dərin öyrənməyə içi qızılla dolu qara qutu kimi baxa bilirlər. Məsələ burasındadır ki, dərin öyrənmə həqiqətən də maşın öyrənməsinin aktuallaşmasına səbəb olmuş, şəkillərdə, səslərdə tanıma məsələlərinin inkişaf yoluna işıq tutmuşdur və geniş istifadə olunur. Zənnimcə, dərin öyrənmənin anlaşılmasına, sahə ilə məşğul olanların zehnindəki qara qutunun divarlarının şəffaflaşdırılmasına ehtiyac var və ümid edirəm, bu publisistik məqalə həmin məqsəd yönündə Azərbaycan dilində resursların artması nöqteyi nəzərindən mühüm addım olacaq.
Dərin öyrənmənin başa düşülməsi üçün aşağıda qeyd olunanlardan məlumatlı olmaq lazımdır:
- Həllində maşın öyrənməsindən istifadə olunan sinidləşdirmə məsələsinin qoyuluşu, həlli mərhələləri, bəzi anlayışlar
- Süni Neyron Şəbəkə və onun tədqiqat işlərində keçdiyi inkişaf yolu
- “Convolution” və “puling” əməliyyatları
- Məlum CNN arxitekturalarından biri
Ömər Bayramovun TechNet-dəki məqaləsində maşın öyrənməsinin növləri barədə danışılıb. Lakin mən danışacaqlarımın anlaşılması üçün təkrara düşmək riskini nəzərə almadan özüm qısa izah verməyi üstün tuturam, çünki nəticədə Ömər bəyin məqaləsini oxuyanlar bəzi nüanslara yenidən diqqət etməklə çox bir şey itirməyəcəklər.
Maşın öyrənməsi dedikdə birbaşa öyrədilmədən öz-özünə, yəni nümunələr əsasında həll yolunun tapılması nəzərdə tutulur. Belə bir konsepsiyaya aşağıdakı səbəblərdən birinə görə ehtiyac duyuruq:
- Bəzən həllin analitik yolunu heç biz insanlar özümüz də bilmirik.
- Ola bilsin, bəzən bilirik, amma onu kompüterə izah edə, kompüterin anlayacağı dildə ifadə edə bilmirik.
- Bəzən analitik həll yolunu bilirik, kompüterə izah da edə bilirik, amma bu həlli kompüterin reallaşdırması, həlli bu birbaşa öyrətdiyimiz yolla tapması üçün çoxlu resurs və vaxt tələb olunur və s.
2. Həllində maşın öyrənməsi istifadə olunan məsələlərdən birinin – sinifləşdirmə məsələsinin qoyuluşu
Maşın öyrənməsi təklif etdiyi həll yanaşmalarını aşağıdakılara bölmək olar, başqa sözlə, maşın öyrənməsinin aşağıdakı növləri var:
- Müəllimlə öyrənmə (ing. supervised learning)
- Müəllimsiz öyrənmə (ing. unsupervised learning)
- Qarışıq öyrənmə (ing. semi-supervised learning)
- Nəticə əsaslı öyrənmə (ing. reinforcement learning)
Mən bu növlərdən 2-cisindən başlayıb 1-cisinə keçəcək, məqalənin həcmini artırmamaq üçün digər iki növə aid nəsə deməyəcəyəm. Amma bundan əvvəl “əlamət” (ing. feature) nədir, onu başa düşmək lazımdır.
Maşın öyrənməsinin fərqli növlərinin işlədilməsindən asılı olaraq hər nümunə giriş və ya giriş-çıxış vektorları kimi ilə ifadə olunur. Həmin nümunənin hansısa bir obyekt (məs. banka kredit almaq üçün gələn müştəri, hansısa şəkil və s.) haqqında bir müşahidə olduğunu qəbul eləsək, həmin nümunənin girişi obyektin əlamətləri, çıxışı modelin obyekt əsasında tapması arzu olunan cavabıdır. İş burasındadır ki, obyektin ilkin verilənləri (məs. rastr qrafikası ilə təsvir olunan şəklin pikselləri) obyekti anlamaq, digər obyektlərdən ayırmaq və s. üçün, adətən, kifayət qədər informativ olmur, onda biz bu ilkin verilənlər əsasında elə əlamətlər çıxarmağa çalışırıq ki, ondan istifadə etməklə obyekti əhatəli şəkildə təsvir edə bilək.
Maşın öyrənməsinin müəllimsiz öyrənmə növündə biz nümunələr kimi sadəcə girişləri, yəni hər obyektin əlamət dəstini yığırıq, sonra bu əlamət dəstlərinin yaxınlığı əsasında obyektləri qruplaşdırırıq. Burada qruplar özü-özlüyündə mənalı deyil, əsas nüans bazadakı obyektlərin əlamət fəzasında (ing. feature space) bir-birinə nəzərən yaxın və ya uzaq yerləşməsi əsasında klasterlərə ayrılmasıdır. Bu proses klasterizasiya və ya klasterləmə adlandırılır.
Müəllimlə öyrənmədə isə proqnoz verən model (ing. predicting model) qurulur. Belə bir modeldən bazadakı nümunələr – giriş-çıxış cütləri əsasında əlaməti verilmiş obyektin çıxışı olacaq hansısa ədədləri və ya həmin obyektin sinfini proqnozlaşdırmaq tələb olunur. Birinci tapşırığa reqresiya, ikincisinə sinifləşdirmə deyilir. Bəzi üsullar reqresiya üçün (məs., xətti və qeyri-xətti reqresiyalar və s.), bəziləri isə sinifləşdirmə üçün (məs., logistik reqresiya, K Nearest Neghbours, Support Vector Machines və s.), süni neyron şəbəkə isə hər ikisi üçün istifadə oluna bilir. Bizə bu məqalədə süni neyron şəbəkənin sinifləşdirmə üçün istifadəsini nəzərə almaq kifayətdir, çünki CNN-lər, əsasən, sinifləşdirmə üçün istifadə olunur. Və burada sinif anlayışına aydınlıq gətirmək lazım gəlir. Sinif anlayışı klasterdən fərqlənir, çünki sinif özü-özlüyündə məna ifadə eləyir. Məs., bizdən ola bilsin verilmiş şəkil əsasında əsasında şəklin kişi, yoxsa şəkli olduğunu proqnozlaşdıran model qurmaq tələb olunursa, bu o deməkdir ki, quracağımız model sinifləşdirmə modelidir, verilmiş şəkli kişi və ya qadın sinfinə aid edir, burada iki sinfin də mahiyyəti aydındır. Amma tutaq ki, bizə hansısa bir bankın minlərlə müştərisinin hər birinin əlamət dəsti verilib, biz onları yaxınlıqları əsasında 10 qrupa – klasterə bölməliyik, hansı ki, sonra bu qrupların hər birinə ayrı-ayrı məbləğdə kreditlər təklif olunacaq, bu halda biz həmin 10 klasterin mənasını anlamırıq. Amma emaillərin məzmunları əsasında hər emaildən əlamət çıxarıb, çoxsaylı belə obyektlər – emaillər yığıb, bu emaillərin hansılarının spam olduğunu, hansılarının olmadığını qeyd edərək email və spam olub-olmamağı bildirən ədədlərin cütlərindən ibarət baza hazırlayıb, bir sinifləşdirmə modelinə öyrətsək, yeni bir email veriləndə model deyəcək ki, bu email spamdir, yoxsa deyil və aydın məsələdir ki, bu siniflərin hər birinin – spam olanının da, olmayanının da mənası var və biz bunu bilirik. Və ya tutaq ki, bizdən əl ilə yazılmış rəqəm təsviri əsasında rəqəmin tanınması məsələsini həll etmək tələb olunur. Biz bu halda fərqli insanlara rəqəmlər yazdırıb, şəkil çəkməklə rəqəm şəkilləri nümunələri yığarıq, sonra hər rəqəm şəklinin hansı rəqəm olduğunu aydınlaşdırarıq, beləcə rəəqm şəkli və hansı rəqəm olduğundan ibarət cütlərdən baza (ing. dataset) yığarıq, sonra həmin bazadakı nümunələri öyrətmə və test bazalarına (ing. training set and test set), məs., 80:20 nisbətində bölərik, öyrətmə bazasındakı nümunələrdən istifadə edərək modeli öyrədərik ki, bu rəqəm şəkli olanda bizə bu rəqəmə uyğun nəticəni versin. Model öyrətmə bazasının köməyi ilə öyrədildikdən sonra test bazasındakı nümunələrin girişini modelə verib modeldən aldığımız çıxışla test bazasındakı real çıxışı müqayisə edərək modelin performansını qiymətləndirərik. Nəhayət testləşdirmə modelin tanımada müvəffəqiyyəti ilə bitdikdə inanmaq olar ki, yeni əl ilə yazılmış yeni bir rəqəm şəklinin əlaməti çıxarılıb modelə verildikdə model bizə onun hansı rəqəmin şəkli olduğunu bildirəcək.
Əlavə olaraq demək lazımdır ki, bu gün bizim sinifləşdirmə – ing. classification adı ilə tanıdığımız məsələ surətlərin tanınması (ing. “pattern recognition”) adı ilə də tanınır və ilk bioloji neyron üzərində tədqiqatlardan dərin öyrənməyə gedən yolun məqsədi şəkillərdə təsvir olunan obyektlərin surətlərin tanınması məsələlərinin həll olunması olub.
3. Dərin öyrənməyə gətirib-çıxaran inkişaf yolu
Surətlərin tanınması, maşın öyrənməsi kimi konsepsiyalar qısa zamanda uzun inkişaf yolu keçmişdir. Hələ 1943, 1947-ci illərdə Makallok və Pits sadə beyin hüceyrəsinin davranışını tədqiq etmişdilər. 1957-cı ildə Rozenblat neyronun “perseptron” adlandırdığı hesablama modelinin öyrədilməsi üçün alqoritm təklif etmişdir. 1960-cı illərin əvvəllərində Uidrou və Haf ADALİN (ing. ADALIN, ADAptive LINear Elements) adlandırdıqları perseptronvari sistemlər üzərində bəzi məsələlərin həllini nümayiş etdirdilər. Həmin müəlliflər “ən kiçik orta kvadratlar” adlandırdıqları perseptronvari aparatların öyrədilmə alqoritmini də təklif etmişdirlər. 1969-cu ildə Minski və Peypert perseptronları ciddi şəkildə təhlil etmiş və belə qənaətə gəlmişdilər ki, birlaylı süni neyron şəbəkələrin aproksimasiya imkanlarında ciddi məhdudiyyətlər var. O zamanlar hələ çoxlaylı süni neyron şəbəkənin məlum öyrədilmə alqoritmi mövcud deyildi. Bununla yanaşı Hornik və həmmüəlliflərin 1989, 1990-cı illərdəki işlərində də istifadə olunan süni neyron şəbəkənin aproksimator kimi istifadə imkanlarını araşdırmışdır. Nəhayət 1974-ci ildə Uerbos, 1985-ci ildə Parker, 1986-cı ildə Rumerlhart və həmmüəllifləri bir-birilərindən xəbərsiz “error backpropagation” və ya xətaların geriyə ötürülməsi adlanan çoxlaylı süni neyron şəbəkələrin öyrənmə alqoritmini təklif etdilər.
Surətlərin tanınması məsələlər sinfinin bir alt sinfi kimi təsvirlərin tanınması üçün də modellər işlənilmiş, yeni model növləri təklif olunmuşdur. 1962-ci ildə neyrofizioloqlar Hyubel və Uiselin tədqiqatları mühüm dönüş nöqtələrindən biridir. Müəlliflər pişiklərin vizual idrakını tədqiq edərək belə nəticəyə gəlmişdilər ki, görmənin ilk mərhələsində görüntüdən, məs., vertikal və horizontal xəttlər kimi sadə əlamətlər çıxarılır, sonra hər mərhələdə əvvəlki mərhələdə alınan nəticədən əlamət çıxarılır. Yəni bioloji görmədə ənənəvi tanıma məsələlərindəki kimi əlamət çıxarılışı sadəcə başlanğıcda yox, prosesin digər mərhələlərində də davam edir. Bu yeni biliklərə əsaslanaraq Fukuşima 1980-ci ildə “Neokoqnitron” (ing. Neocognitron) adlanan şəbəkəni təklif etdi. Sonradan Hyubel və Uiselin ideyaları dərin öyrənmənin ərsəyə gəlməsinə təkan verdi. Nəticədə LiKun, Krizevski və Hinton dərin öyrənmə üsulları və dərin öyrənən şəbəkələrin işlənilməsində iştirak etdilər, öz tövhələrini verdilər. Beləcə bükülmə neyron şəbəkə istifadə olunmağa başlandı, yeni arxitekturalar təklif olundu və olunmağa davam edir.
Nəticə etibarı ilə Süni Neyron Şəbəkələr (obyektin giriş verilənləri əsasında çıxarılmış) əlamətlərlə çıxışı – obyektin sinfi arasındakı əlaqəni öyrənir (ing. “traditional” machine learning), Bükülmə Neyron Şəbəkə (ing. Convolutional Neural Network) təkcə əlamətlə çıxış arasındakı əlaqə yox, həm də öyrətmə bazasına (ing. training set) uyğun gələn əlamətləri öyrənir ki, biz bunu dərin öyrənmə (ing. deep learning) adlandırırıq.
4. Süni neyron şəbəkə (ing. Artificial Neural Network, ANN)
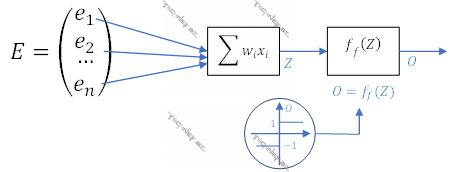
ANN-ləri başa düşmək üçün əvvəla insanın beyin hüceyrəsinin – bioloji neyronun işini, sonra bioloji neyron əsasında süni neyronun modelini, aktivasiya funksiyalarını və nəhayət çoxlaylı süni neyron şəbəkələri (ing. Multilayer Artificial Neural Networks) başa düşmək lazımdır.
4.1. Süni və bioloji neyron
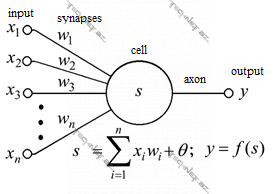
ANN-lərin fəaliyyəti insan beyninin bioloji quruluşuna əsaslanır. Orta insan beynində 1011-ə yaxın sinir hüceyrəsi – neyron olur. Hər belə neyron 10000-ə qədər digər neyronla əlaqələr qura bilir və beləliklə neyronlararası əlaqələrin sayı 1015-ə çatır. Bu əlaqələr vasitəsi ilə bir neyrondan digərinə elektrik və ya kimyəvi siqnal ötürülür. Neyronun membranındakı gərginlik müəyyən bir dəyəri aşdıqda digər neyronlara siqnal ötürür. Sinir sisteminin işi bu neyronların bu cür əlaqəsinə əsaslanır. Reseptor sinirlərdən alınan siqnal şəbəkəyə ötürülür, siqnal emal olunaraq effektor sinirlərə daşınır.
20-ci əsrin 50-ci illərində Makkallok və Pits insanın sinir hüceyrələrinin fəaliyyətinin hesablama modelini tədqiq etməklə, bioloji neyronun imitasiyası olan süni neyronun hesablama modeli kimi istifadəsinə yol açdılar. Bioloji neyronun işi aşağıdakı şəkildə təsvir olunmuşdur.
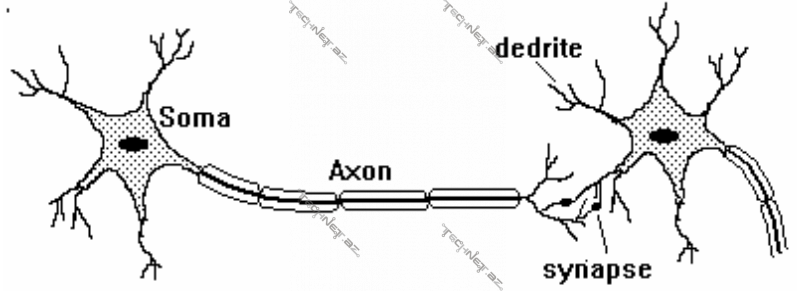
Bioloji neyronda dendritlər vasitəsi ilə digər neyronlardan alınan siqnal hüceyrənin nüvəsinə keçir. Neyronda aktivlik olduqda siqnal digər neyronlara aksonlar vasitəsi ilə ötürülür. Bioloji neyronda süni neyronun dendritlərinin analoqu kimi girişlər, nüvədə baş verənlərin imitasiyası kimi girişlərin çəkilər (ing. weights) nəzərə alınaraq cəmlənməsi, bioloji aktivləşmənin baş verib-verməməsi kimi aktivasiya funksiyası dayanır. Aşağıdakı şəkildə 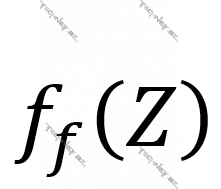 aktivasiya funksiyasıdır, xəttiliyi aradan qaldıraraq laydan laya keçidlərin ANN-in aproksimasiya, yəni öyrənmə imkanlarının xətti yox, qeyri-xətti artırılması üçün istifadə olunur.
aktivasiya funksiyasıdır, xəttiliyi aradan qaldıraraq laydan laya keçidlərin ANN-in aproksimasiya, yəni öyrənmə imkanlarının xətti yox, qeyri-xətti artırılması üçün istifadə olunur.
4.2. Aktivasiya funksiyaları
Bioloji neyron ona daxil olan siqnallar müəyyən bir həyəcanlandırma əmsalını aşdıqda həyəcanlanır və elektrik buraxırsa, süni neyronda da həyəcanlandırma, yəni aktivasiya funksiyası neyronun çıxış qiymətinə təsir edir. Aktivasiya funksiyasına nümunə kimi aşağıdakı qeyri-xətti funksiyaları istifadə etmək olar:
- Vahid sıçrayış funksiyası:
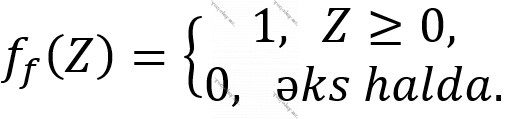
- Siqmoid funksiyası:
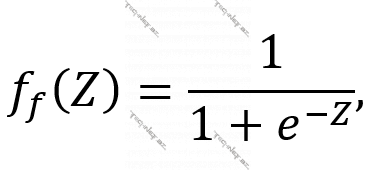
harada ki,  .
.
- Hiperbolik tangens funksiyası:
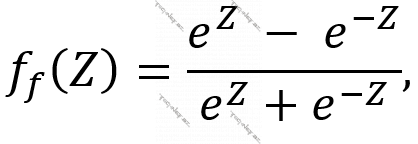
harada ki,  .
.
- Softmaks funksiyası. Adətən, şəbəkənin çıxışında vektor alındıqda, başqa sözlə, şəbəkənin son layında birdən çox neyron olduqda, xüsusən, sinifləşdirmə məsələlərində (ing. “OneHotEncoding”-i dəstəkləmək mahiyyəti daşımaqla) geniş istifadə olunur. Son laydakı hər neyronun çıxış qiyməti aşağıdakı kimi tapılır:
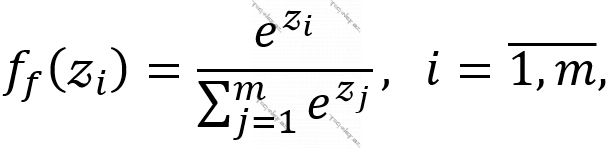
burada,  son laydakı neyronların uyğun giriş siqnallarının uyğun çəkilərlə skalyar hasilinin həyəcanlandırma əmsalı ilə cəmləridir və növbəti bərabərlik doğrudur:
son laydakı neyronların uyğun giriş siqnallarının uyğun çəkilərlə skalyar hasilinin həyəcanlandırma əmsalı ilə cəmləridir və növbəti bərabərlik doğrudur: 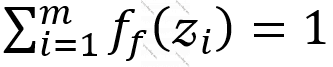 .
.
- “Rectified Linear Unit” (ReLU) funksiyası. İlk dəfə 2010-cı ildə təklif olunmuşdur. 2018-ci ildə archive.org saytında dərc olunan məqalədə ReLU aktivasiya funksiyasının dərin öyrənmənin tətbiq olunduğu işlərdə “susmaya görə” mahiyyətini daşıyır. Çox sadə olmasına baxmayaraq xəttiliyi aradan qaldırır və yaxşı nəticə verir. Analitik ifadəsi aşağıdakı kimidir:
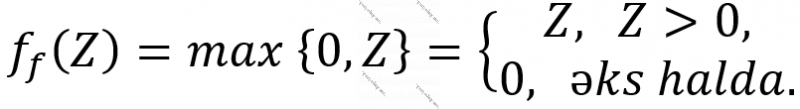
4.3. Çoxlaylı ANN-lərin öyrədilməsi
Birdən çox layda çoxsaylı neyronun əlaqəli işi çoxlaylı ANN adı altında ifadə olunur və approksimasiya imkanının genişliyi layların, laylardakı neyron sayları və aktivasiya funksiyalarının seçimi ilə təyin olunur (aşağıdakı şəkillər). Çoxlaylı ANN-in tam əlaqəli növü surətlərin tanınması məsələsində xüsusi yer tutur. Belə tam əlaqəli ANN-lərin girişinə surətin əlaməti verildikdə əlamətin əvvəlcədən mahiyyəti bilinən siniflərdən hansına uyğun gəldiyi tapılır. Lakin belə bir şəbəkəni işlətməzdən əvvəl xətanın geriyə yayılması (ing. error backpropagation) adlanan yanaşmanın köməyi ilə öyrətmə bazasını modelə öyrətmək lazım gəlir.

Perseptron 
Çoxlaylı ANN
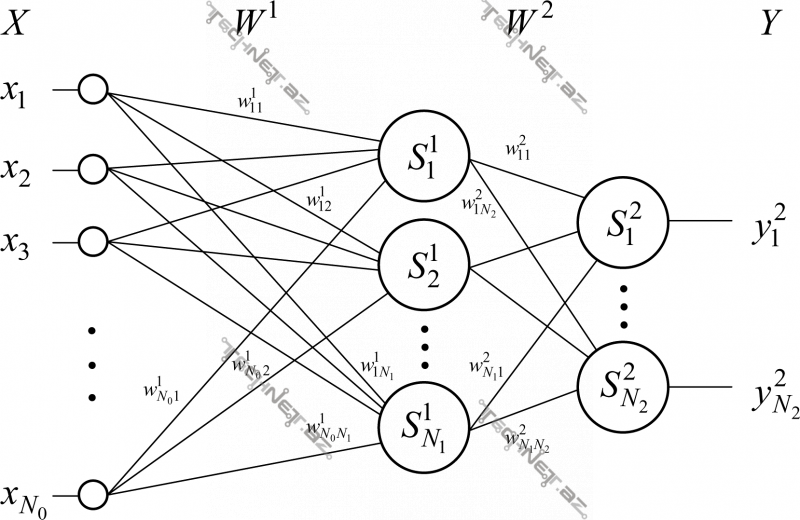
Ümumilikdə, şəbəkənin hazırlanması iki mərhələdə aparılır:
- Struktur seçimi. Bu mərhələdə layların və laylardakı neyronların sayı, fərqli laylardakı neyronların necə əlaqələndiriləcəyi – aktivasiya funksiyaları seçilir.
- Parametrlərin seçimi. Şəbəkədə neyronlar arasındakı sinaps qiymətləri və neyronların həyəcanlandırma əmsallarının qiymətləri təyin olunur.
2-ci mərhələ xətanın geriyə yayılması (ing. backpropagation) vasitəsi ilə aparılır. Bunun üçün şəbəkədə son laydan ilk laya doğru getməklə sinaps və həyəcanlandırma əmsallarına görə müəyyən məqsəd funksiyasının xüsusi törəmələri rekursiv şəkildə tapılır. Daha doğrusu, sonuncu laydakı həyəcanlandırma əmsalları və sonuncu laya bitişik, o layı formalaşdıran çəki – sinaps qiymətlərinə görə törəmələr birbaşa tapılır, ondan əvvəlki laydakı parametrlər isə hər biri özündən sonrakı laya əsaslanaraq tapılır.
Başqa sözlə “backpropagation”-ın köməyi ilə ANN modellərinin öyrədilməsi dedikdə neyronlar arası əlaqələrin – sinapsların ədədi qiymətləri və həyəcanlandırma əmsalları qiymətlərinin optimallaşdırma ilə təyinini nəzərdə tuturuq. Burada optimallaşdırılan xəta/məqsəd funksiyası (ing. cost/objective function) itki funksiyasından (ing. loss function) seçilir ki, TechNet-dəki başqa bir məqaləmdə Keras kitabxanasındakı itki funksiyalarını sadalamış, izahlarını, istifadə yerlərini qeyd etmiş, üstəlik ən kiçik kvadratlar üsulunun (ing. least squares approach) xətti reqresiya (ing. linear regression) məsələsinin həllinə tətbiqini düsturlarla vermişdim. Məqaləni diqqətlə oxuyanların başa düşə biləcəyi kimi orada xətti funksiyasının parametrləri, yəni f(x) = ax + b düsturundakı a və b-ni tapmağa çalışırdıq. ANN bundan daha çox aproksimasiya imkanına sahib olan riyazi funksiya (reqresiya məsələsində) və ya funksiyalar toplusudur (ing. “classification” məsələsində, “OneHotEncoding”-lə). ANN-in öyrədilməsi – öyrətmə bazasındakı (ing. training set) nümunələrə uyğunlaşdırılması üçün biz yenə parametrlərin optimal qiymətlərini hesablamalıyıq. Hansısa optimallaşdırma alqoritmi istifadə etmək üçün bizə məqsəd funksiyasının həmin parametrlərə görə xüsusi törəmələrinin qiymətlərini hesablaya bilmək lazımdır. “Backpropagation” sonuncu qeyd olunan üçündür. Xüsusi törəmələrdən ibarət qradient vektoru tapıldıqdan sonra sürətli enmə üsulu (ing. Gradient Descent) kimi üsullardan istifadə etməklə optimallaşdırma aparılır, training set-dəki nümunələrin çıxışıları ilə ANN-in çıxışı arasındakı fərq optimallaşdırılmağa, minimallaşdırılmağa çalışılır. “Backpropagation”, optimallaşdırma, “training regimes” və s. kimi məsələlər tamamilə ayrı bir məqalənin mövzusu olmalı olduğundan bu məqalədə onlara yer verilməyib. Bu məqalədə ANN-dən danışılması sadəcə CNN-lərin, yəni dərin neyron şəbəkələrin anlaşılması məqsədi daşıyır.
Bunlara baxmayaraq mən magistr dissertasiyamı da bura qoyuram ki, maraqlananlar girib “backpropagation”-a nəzər sala bilsinlər. O cümlədən qeyd edim ki, magistr dissertasiyasında KNN, Naive Bayes Classifier, k-means və s. üsulların izahı və çıxarılışı verilib:
5. Dərin Neyron Şəbəkələr
Bükülmə Neyron Şəbəkə (ing. Convolutional Neural Network). Ənənəvi Bükülmə Neyron Şəbəkə (CNN) bir və ya birdən çox bükmə (ing. convolution) və “puling” layları bloku və tam əlaqəli laylar (ing. fully connected layers) adlanan ANN-dəki perseptronlardan ibarət laylar blokundan ibarətdir. Əslində buradakı “convolution” əməliyyatını şəkillərin filtirlənməsində biz hamımız istifadə etmişik. Bu filterlər həmin əməliyyatın ədədlərdən ibarət matris şəklindəki nüvələrinə (ing. core) görə dəyişir. Bükmə və ya “convolution” əməliyyatı CNN-lərdə əlamət çıxarılışı mexanizmi kimi istifadə olunur və həmin filterin nüvəsindəki ədədlər dərin öyrənmə zamanı öyrətmə bazasına görə optimallaşdırma nəticəsində alınır. Yəni dərin öyrənən şəbəkələrdə təkcə tam əlaqəli laylardakı neyronların parametrləri yox, həm də həmin “convolution” filterlərinin nüvələrinin qiymətləri öyrənilir, dərin öyrənmə də buna deyilir. Əlavə olaraq qeyd etmək lazımdır ki, “puling” təsviri ümumiləşdirməklə ölçüsünü kiçildir.
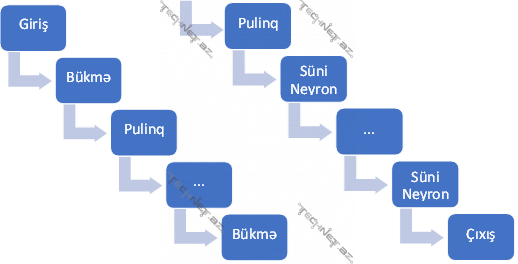
5.1. “Convolution” və “puling” əməliyyatları
Bükmə (ing. convolution) və “puling” əməliyyatları aşağıdakı kimi aparılır:
- Bükülmə əməliyyatı. Şəkil
 , bükülmənin nüvəsi
, bükülmənin nüvəsi  olduqda bükmə əməliyyatının nəticəsi olacaq şəkli
olduqda bükmə əməliyyatının nəticəsi olacaq şəkli  deyə işarə etsək, aşağıdakı doğrudur:
deyə işarə etsək, aşağıdakı doğrudur:
 , bükülmənin nüvəsi
, bükülmənin nüvəsi 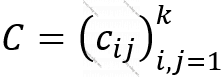 olduqda bükmə əməliyyatının nəticəsi olacaq şəkli
olduqda bükmə əməliyyatının nəticəsi olacaq şəkli 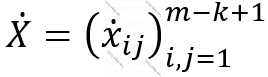 deyə işarə etsək, aşağıdakı doğrudur:
deyə işarə etsək, aşağıdakı doğrudur: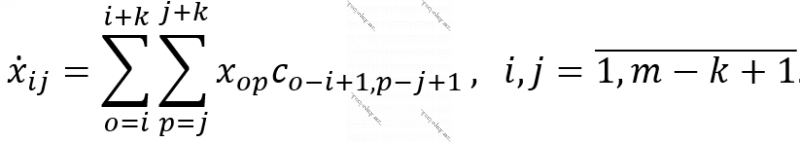
Bükülmə əməliyyatı zamanı təsvirdən regionların necə çıxarılacağını bildirən iki xarakteristika var:
- Addım genişliyi. Bu xarakteristika inglisdilli ədəbiyyatda “stride” adlanır, regionu bildirən çərçivənin sütunlar və sətirlər üzrə neçə xana – piksel hərəkət etməsini bildirir. Susmaya görə
 götürülür.
götürülür. - Əhatəliliyin miqdarı. Bu xarakteristika isə inglisdilli ədəbiyyatda “padding” adlanır, regionlar çıxarılarkən təsvirin sərhədlərindəki xanalara nə qədər əhəmiyyət verildiyini göstərir. Susmaya görə götürülür, əhatəliliyin miqdarından asılı olaraq şəklin sərhədinə boş – ağ və ya qara piksellər əlavə olunur.
(1.1.28)-də təsvir olunmuş əməliyyatda addım genişliyi və əhatəliliyin miqdarı susmaya görə olduğu kimidir, nəticədə (m-k+1)x(m-k+1) ölçülü çevrilmiş təsvir alınır. Addım genişliyi və əhatəliliyin miqdarını s və p götürsək, alınmış yeni təsvirin ölçüsü ((m-k+p)/s+1)x((m-k+p)/s+1) olacaq.
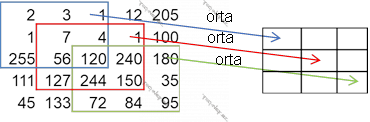
- Pulinq əməliyyatı. BNŞ-lərdə bükülmə laylarından əlavə pulinq laylarından da istifadə olunur. Bu lay ümumiləşdirməyə/icmala kömək etməklə SNŞ-lərin mühüm komponentini təşkil edir. Ədədlərdən və ya vektorlardan ibarət matris formasında verilmiş şəkildən düzbucaqlı şəklində regionlar çıxarılır, həmin region matrisi üzərində əməliyyat aparılır. Çıxarılan regionların ölçüsü eynidir, əvvəlcədən verilir.
Şəkil 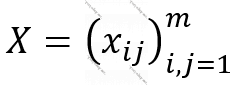 və şəkildən çıxarılan region k x k ölçülü olarsa, pulinq əməliyyatının nəticəsində alınacaq şəkil
və şəkildən çıxarılan region k x k ölçülü olarsa, pulinq əməliyyatının nəticəsində alınacaq şəkil 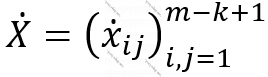 olacaq.
olacaq.
Ümumilikdə bükülmə neyron şəbəkələrdə pulinq əməliyyatının iki növündən geniş istifadə olunur.
- Orta qiymət. Bu yanaşma ilə seçilmiş regiondakı piksellərin ədədi ortası tapılır. Pulinq əməliyyatı ilə çevrilmiş şəklin pikselləri aşağıdakı kimi müəyyən olunur:
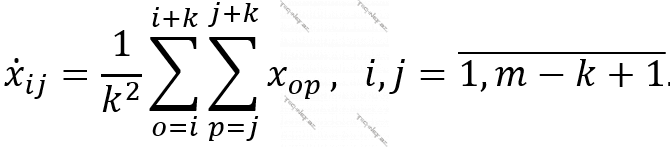
- Maksimum. Bu yanaşma ilə seçilmiş regiondakı piksellərin maksimumu tapılır. Həmin pulinq əməliyyatı ilə çevrilmiş şəklin pikselləri aşağıdakı kimi müəyyən olunur:


Average Pooling 
Max Pooling

5.2. CNN arxitekturaları və onların növləri
Məlum BNŞ Arxitekturaları. BNŞ-nin fərqli arxitekturaları mövcuddur. Bu arxitekturalar aşağıdakı xarakteristikalara görə bir-birindən fərqlənir:
- giriş şəklinin ölçüsü,
- bükmə və pulinq layların sayı,
- fərqli bükmə laylarındakı bükmə əməliyyatlarının sayı,
- bükmə əməliyyatının nüvəsinin ölçüsü,
- pulinq əməliyyatı zamanı təsvirdən çıxarılan regionların ölçüsü,
- tam əlaqəli süni neyronlar laylarının sayı və həmin laylardakı neyronların sayı,
- məsələnin qoyuluşu.
Yuxarıdakılardan sonuncusuna görə bükülmə neyron şəbəkə arxitekturaları üç cür olur:
Birinci növ BNŞ arxitekturaları obyektlərin təyin olunması (ing. object detection) məsələsində istifadə olunur. Obyektlərin tanınması məsələsi təsvirdəki obyektlərin vizual surətlərinin yeri, ölçüsü və sinfinin tapılmasını həyata keçirəcək modelin hazırlanması ilə həll olunur. Region-based CNN, SPP-Net, Fast R-CNN, Faster R-CNN, Mask R-CNN, YOLO kimi obyektlərin təyin olunması şəbəkələri mövcuddur.
İkinci növ bükülmə neyron şəbəkə arxitekturaları təsvirlərin nümunələr əsasında seqmentləşdirilməsi (ing. instance segmentation) üçün istifadə olunur. Təsvirlərin seqmentləşdirilməsi məsələsində hər biri rəng ifadə edən piksellərdən ibarət matrisin hansı xanalarının hansı obyekt olduğu verilmiş təsvirin məqsədə uyğun rənglənməsi ilə aydınlaşdırılır. Fully Convolutional Network (FCN), DeepLab, SegNet və s. arxitekturalar mövcuddur.
Nəhayət üçüncü növ məlum bükülmə neyron şəbəkə arxitekturaları təsvirlərin sinifləşdirilməsi üçün istifadə olunur.
5.3. Təsvirlərin sinifləşdirilməsi üçün istifadə olunan bəzi CNN arxitekturaları
Bu halda təsvirdə bir obyekt var və həmin təsvir obyektin surətidir. Belə arxitekturalardan bəziləri aşağıdakılardır:
- LeNet-5. Bu arxitektura 1998-ci ildə Yan LeCun tərəfindən təklif olunmuş, MNIST adlanan əlyazma rəqəm şəkillərindən ibarət baza ilə sınanmışdır. 60000-ə yaxın öyrədilə bilən parametri var.

LeNet-5 arxitekturalı CNN
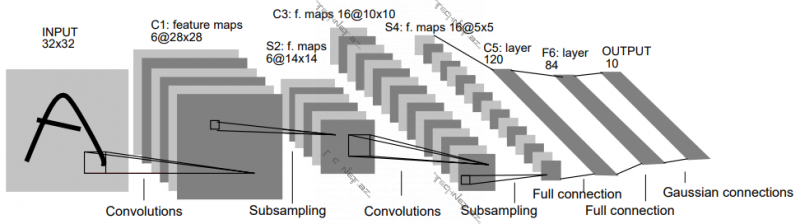
- AlexNet. 2012-cu ildə ImageNet Large-Scale Visual Recognition Challenge (ILSVRC) adlanan və hər il aparılan yarışda təxminən 1000 sinfin müşahidələrindən ibarət haradasa 1.2 milyona yaxın müşahidənin olduğu baza ilə ən aşağı xəta dərəcəli modellər arasında birinci yerə layiq görülmüşdür. Arxitekturanın təqdim olunduğu əsas məqalənin müəlliflərindən biri Cefrey Hintondur. Şəbəkəyə giriş kimi 224 x 224 x 3 ölçülü şəkil götürür, ümumilikdə 60 milyona yaxın parametri var.
- ZFNet. ILSVRC-2013 yarışında AlexNet-i geridə qoymuşdur. AlexNet-dən fərqli olaraq bükmə nüvəsi 11 x 11 yox, 7 x 7 ölçülüdür, əhatəliliyin miqdarı isə 4 yox, 2 götürülmüşdür.
- VGGNet. 2014-cü ildə təqdim olunmuşdur. AlexNet-ə nəzərdə daha dərin şəbəkə hesab olunur, ən məhşur arxitekturalardandır. Bu arxitekturanın sınanmasıyla kiçik ölçülü bükmə nüvələrinin çoxsaylı istifadəsi böyük ölçülü bükmə nüvələrinin effektivliyini əvəz edə bildiyi aydınlaşdırıldı. Daha dərin şəbəkə qurmağa bu imkan verir.
- GoogLeNet. 8 laylıAlexNet-dən fərqli olaraq 22 laylıdır, amma parametr sayı AlexNet-in parametr sayından 12 dəfə azdır. ILSVRC-2014 yarışının qalibidir.
- ResNet. Qradient probleminin həlli üçün bir ideya təklif olunur. ILSVRC-2015 yarışının qalibidir.
- DenseNet. ILSVRC-2016 yarışının qalibidir.
6. İllustrativ nümunə (kodlar və nəticələrlə)
Rəqəm təsvirlərindən ibarət “mnist” dataseti üzərindəki nümunəyə baxaq. Kodları Githubda da bölüşmüşəm.
Mnist dataseti 60000 nümunəli training set və 10000 nümunəli test setdən ibarətdir. Şəkillər 20 x 20 ölçüsündədir, 28 x 28 ölçülü ağ təsvirin içərisinə yerləşdirilib.
“Import”lar və digər bəzi detallar aşağıdakı kodlarda verilir:
# Import needed libraries
import tensorflow as tf
from tensorflow import keras
from matplotlib import pyplot as plt
import random
import sklearn
import numpy as np
from tensorflow.keras import datasets, layers, models, losses
from tensorflow.keras import models
from tensorflow.keras.utils import to_categorical
from tensorflow.keras.callbacks import EarlyStopping
from sklearn.metrics import confusion_matrix
import os
# Some Basic Characteristics
random.seed = 42
tf.random.set_seed(42)
im_num_rd = random.randint(0, x_train.shape[0])
im_num_rd
OUTPUT_PATH = 'output/'
MODEL_NAME_ANN = 'ANN-784-64-64-10'
MODEL_NAME_CNN = 'CNN-LeNet5'
if not os.path.exists(OUTPUT_PATH):
os.makedirs(OUTPUT_PATH)
Mnist dataseti yüklənilir:
# Load MNIST data
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
print('Train:', x_train.shape)
print('Test:', x_test.shape)
Şəkillərə nəzər salaq:
# METHOD: show multiple images to look through the dataset
def plot_images(images, file_name = None, r=10, c=10):
fig = plt.figure()
for i in range(1, r):
for j in range(1, c):
axs = fig.add_subplot(r,c,(i-1)*c+j)
axs.set_xticks([])
axs.set_yticks([])
axs.imshow(images[(10*i)+j].reshape(28, 28), cmap=plt.cm.gray_r)
plt.show()
if file_name is not None:
fig.savefig(os.path.join(OUTPUT_PATH, file_name + '.jpg'))
plot_images(x_train, '100-images')

Data üzərində təmizləmə aparılır:
# Clean data
x_train = x_train.astype(float) # Change data type of x_train
x_test = x_test.astype(float) # Change data type of x_test
x_train /= 255 # Normalize pixel values
x_test /= 255 # Normalize pixel values
y_train = to_categorical(y_train) # OneHotEncoding for y_train
y_test = to_categorical(y_test) # OneHotEncoding for y_test
print('y_train:', y_train.shape)
print('y_test:', y_test.shape)
ANN və CNN-lərdə istifadə olunacaq hyperparametrlər təyin olunur:
# Specify hyperparameters for ANN and CNN
EPOCHS = 200
callback = EarlyStopping(monitor='loss', min_delta=0.01, patience=5)
POOL_CHOICE = layers.AveragePooling2D
PADDING_CHOICE = 'valid'
KERNEL_SIZE = (5,5)
POOL_SIZE = (2,2)
ACT_FUNC = keras.activations.relu
OPT = keras.optimizers.Adam
LOSS_FUNC = keras.losses.categorical_crossentropy
METRICS = ['accuracy',
'mse', 'mae']
#keras.metrics.Precision(), keras.metrics.Recall()
ANN modelinin strukturu verilir:
# Define structure of the ANN with structure 784-64-64-10
keras.backend.clear_session()
model_ANN = models.Sequential(name = MODEL_NAME_ANN)
model_ANN.add(layers.Dense(64, input_shape = (784,), activation=ACT_FUNC))
model_ANN.add(layers.Dense(64, activation=ACT_FUNC))
model_ANN.add(layers.Dense(10, activation='softmax'))
model_ANN.compile(optimizer = OPT(), loss = LOSS_FUNC, metrics = METRICS)
model_ANN.summary()
Model: "ANN-784-64-64-10" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= dense (Dense) (None, 64) 50240 _________________________________________________________________ dense_1 (Dense) (None, 64) 4160 _________________________________________________________________ dense_2 (Dense) (None, 10) 650 ================================================================= Total params: 55,050 Trainable params: 55,050 Non-trainable params: 0 _________________________________________________________________
LeNet-5 arxitekturalı CNN modelinin strukturu verilir:
# Define structure of the CNN with LeNet-5 architecture
keras.backend.clear_session()
model_CNN = models.Sequential(name = MODEL_NAME_CNN)
model_CNN.add(layers.Conv2D(filters=6, kernel_size=KERNEL_SIZE, padding='same', activation=ACT_FUNC, input_shape=(28, 28, 1)))
model_CNN.add(POOL_CHOICE(pool_size=POOL_SIZE))
model_CNN.add(layers.Conv2D(filters=16, kernel_size=KERNEL_SIZE, padding='valid', activation=ACT_FUNC))
model_CNN.add(POOL_CHOICE(pool_size=POOL_SIZE))
model_CNN.add(layers.Conv2D(filters=120, kernel_size=KERNEL_SIZE, padding='valid', activation=ACT_FUNC))
model_CNN.add(layers.Flatten())
model_CNN.add(layers.Dense(84, activation=ACT_FUNC))
model_CNN.add(layers.Dense(10, activation="softmax"))
model_CNN.compile(optimizer = OPT(), loss = LOSS_FUNC, metrics = METRICS)
model_CNN.summary()
Model: "CNN-LeNet5" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d (Conv2D) (None, 28, 28, 6) 156 _________________________________________________________________ average_pooling2d (AveragePo (None, 14, 14, 6) 0 _________________________________________________________________ conv2d_1 (Conv2D) (None, 10, 10, 16) 2416 _________________________________________________________________ average_pooling2d_1 (Average (None, 5, 5, 16) 0 _________________________________________________________________ conv2d_2 (Conv2D) (None, 1, 1, 120) 48120 _________________________________________________________________ flatten (Flatten) (None, 120) 0 _________________________________________________________________ dense (Dense) (None, 84) 10164 _________________________________________________________________ dense_1 (Dense) (None, 10) 850 ================================================================= Total params: 61,706 Trainable params: 61,706 Non-trainable params: 0 _________________________________________________________________
ANN modeli öyrədilir:
training_history_ANN = model_ANN.fit(x_train.reshape(x_train.shape[0], 784), y_train, epochs = EPOCHS, shuffle = True, callbacks=[callback], verbose=1)
Epoch 1/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.2725 - accuracy: 0.9199 - mse: 0.0121 - mae: 0.0274 Epoch 2/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.1201 - accuracy: 0.9640 - mse: 0.0055 - mae: 0.0119 Epoch 3/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0899 - accuracy: 0.9721 - mse: 0.0043 - mae: 0.0090 Epoch 4/200 1875/1875 [==============================] - 2s 1ms/step - loss: 0.0701 - accuracy: 0.9780 - mse: 0.0033 - mae: 0.0070 Epoch 5/200 1875/1875 [==============================] - 2s 1ms/step - loss: 0.0573 - accuracy: 0.9823 - mse: 0.0028 - mae: 0.0058 Epoch 6/200 1875/1875 [==============================] - 2s 1ms/step - loss: 0.0492 - accuracy: 0.9845 - mse: 0.0024 - mae: 0.0050: 0s - loss: 0.0490 - accuracy: 0.9845 - mse: 0.0024 - mae: 0.00 Epoch 7/200 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0408 - accuracy: 0.9864 - mse: 0.0021 - mae: 0.0043 Epoch 8/200 1875/1875 [==============================] - 2s 1ms/step - loss: 0.0368 - accuracy: 0.9884 - mse: 0.0018 - mae: 0.0037 Epoch 9/200 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0306 - accuracy: 0.9902 - mse: 0.0015 - mae: 0.0032 Epoch 10/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0270 - accuracy: 0.9907 - mse: 0.0014 - mae: 0.0029 Epoch 11/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0252 - accuracy: 0.9918 - mse: 0.0013 - mae: 0.0026 Epoch 12/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0217 - accuracy: 0.9925 - mse: 0.0011 - mae: 0.0023 Epoch 13/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0172 - accuracy: 0.9945 - mse: 8.6643e-04 - mae: 0.0019 Epoch 14/200 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0199 - accuracy: 0.9935 - mse: 0.0010 - mae: 0.0020 Epoch 15/200 1875/1875 [==============================] - 3s 2ms/step - loss: 0.0157 - accuracy: 0.9946 - mse: 8.1189e-04 - mae: 0.0016 Epoch 16/200 1875/1875 [==============================] - 2s 1ms/step - loss: 0.0155 - accuracy: 0.9945 - mse: 8.1679e-04 - mae: 0.0016 Epoch 17/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0141 - accuracy: 0.9950 - mse: 7.3719e-04 - mae: 0.0015 Epoch 18/200 1875/1875 [==============================] - 3s 1ms/step - loss: 0.0156 - accuracy: 0.9944 - mse: 8.3421e-04 - mae: 0.0015
CNN modeli öyrədilir:
training_history_CNN = model_CNN.fit(x_train.reshape(x_train.shape[0], 28, 28, 1), y_train, epochs = EPOCHS, shuffle = True, callbacks=[callback], verbose=1)
Epoch 1/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.2181 - accuracy: 0.9327 - mse: 0.0100 - mae: 0.0215 Epoch 2/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0723 - accuracy: 0.9773 - mse: 0.0034 - mae: 0.0072 Epoch 3/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0513 - accuracy: 0.9834 - mse: 0.0025 - mae: 0.0051 Epoch 4/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0396 - accuracy: 0.9877 - mse: 0.0019 - mae: 0.0039 Epoch 5/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0322 - accuracy: 0.9900 - mse: 0.0016 - mae: 0.0032 Epoch 6/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0267 - accuracy: 0.9915 - mse: 0.0013 - mae: 0.0026 Epoch 7/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0235 - accuracy: 0.9925 - mse: 0.0012 - mae: 0.0023 Epoch 8/200 1875/1875 [==============================] - ETA: 0s - loss: 0.0186 - accuracy: 0.9940 - mse: 9.2582e-04 - mae: 0.00 - 25s 13ms/step - loss: 0.0186 - accuracy: 0.9940 - mse: 9.2532e-04 - mae: 0.0019 Epoch 9/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0175 - accuracy: 0.9939 - mse: 8.8754e-04 - mae: 0.0018 Epoch 10/200 1875/1875 [==============================] - 25s 13ms/step - loss: 0.0144 - accuracy: 0.9951 - mse: 7.2242e-04 - mae: 0.0015 Epoch 11/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0131 - accuracy: 0.9958 - mse: 6.7361e-04 - mae: 0.0013 Epoch 12/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0125 - accuracy: 0.9959 - mse: 6.3563e-04 - mae: 0.0012 Epoch 13/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0110 - accuracy: 0.9963 - mse: 5.6763e-04 - mae: 0.0011 Epoch 14/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0098 - accuracy: 0.9968 - mse: 4.9107e-04 - mae: 9.6352e-04 Epoch 15/200 1875/1875 [==============================] - 24s 13ms/step - loss: 0.0078 - accuracy: 0.9974 - mse: 3.9034e-04 - mae: 7.7204e-04
Modellərin öyrənmə nəticələrinin qrafiki təsviri:
class LengthsDoNotMatchException(Exception):
def __init__(self, length1, length2):
message = f'Lengths of arrays do not match: {length1} vs {length2}'
super().__init__(message)
"""
METHOD: Show metrics obtained during each epoch in training WITH COMPARISONS OVER DIFFERENT MODELS
The metrics are the following:
Loss - Categorical Crossentropy
Accuracy - rate of the accurate/true predictions over all predictions
MSE - Mean Squared Error
MAE - Mean Absolute Error
"""
def plot_training_histories(training_histories, model_names, file_name = None):
if len(training_histories) != len(model_names):
raise LengthsDoNotMatchException(len(training_histories), len(model_names))
loss_histories, acc_histories, mse_histories, mae_histories = [], [], [], []
for i in range(len(training_histories)):
loss_histories.append(training_histories[i].history['loss'])
acc_histories.append(training_histories[i].history['accuracy'])
mse_histories.append(training_histories[i].history['mse'])
mae_histories.append(training_histories[i].history['mae'])
# Define plot size, approximately 1024x1024 pixels
dpi = 300
num_of_pixels = 1024
num_of_inches = num_of_pixels / dpi
cm = num_of_inches * 2.54
plt.gcf().set_dpi(dpi)
fig = plt.figure(figsize=(cm,cm))
plt.subplots_adjust(hspace=0.3)
axs11 = fig.add_subplot(2,2,1)
axs12 = fig.add_subplot(2,2,2)
axs21 = fig.add_subplot(2,2,3)
axs22 = fig.add_subplot(2,2,4)
fig.suptitle('Training Metrics - ' + file_name if file_name is not None else '')
x_ticks = np.arange(1, len(loss_history), 2)
for axs in (axs11, axs12, axs21, axs22):
axs.set_xlabel('epochs')
axs.set_xticks(x_ticks)
for i in range(len(training_histories)):
axs11.plot(loss_histories[i], label = model_names[i])
axs12.plot(acc_histories[i], label = model_names[i])
axs21.plot(mse_histories[i], label = model_names[i])
axs22.plot(mae_histories[i], label = model_names[i])
axs11.set_title('Loss')
axs12.set_title('Accuracy')
axs21.set_title('MSE')
axs22.set_title('MAE')
axs11.legend()
axs12.legend()
axs21.legend()
axs22.legend()
plt.show()
# Save the figure as an image if specified
if file_name is not None:
fig.savefig(os.path.join(OUTPUT_PATH, 'Training Metrics - ' + file_name + '.jpg'))
plot_training_histories(training_histories=[training_history_ANN, training_history_CNN],
model_names=[MODEL_NAME_ANN, MODEL_NAME_CNN], file_name='ANN-CNN')
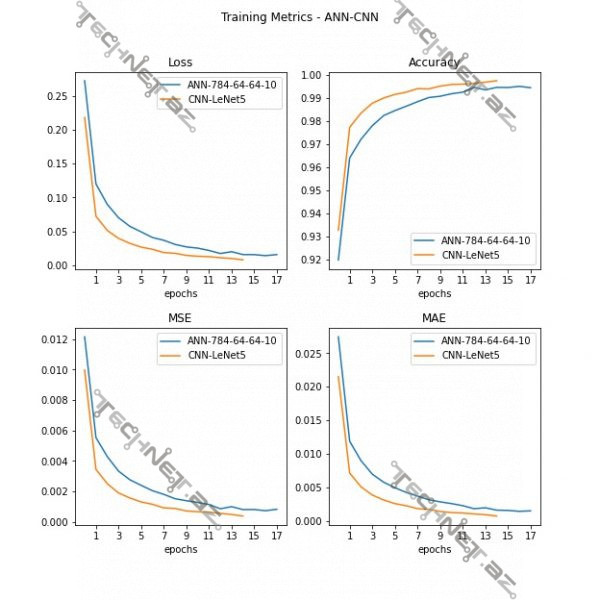
Öyrənmənin detallı nəticələri:
"""
METHOD: Predict and Prep real and predicted labels
"""
def prep_y_true_pred(model, x_test, y_test):
y_pred_one_hot = model.predict(x_test)
y_true = np.argmax(y_test, axis = 1)
y_pred = np.argmax(y_pred_one_hot, axis = 1)
return (y_true, y_pred)
"""
METHOD: Show evaluation metrics over TEST data & estimate confusion matrix
The metrics are the following: Precision, Recall, F1-Score, Support.
"""
def conf_matrix_and_classification_report(y_true, y_pred):
conf_matrix = sklearn.metrics.confusion_matrix(y_true, y_pred)
for i in range(len(conf_matrix)):
print(str(i) + ':', conf_matrix[i])
print('-----------------------------------------------------')
# Print the precision and recall, among other metrics
print(sklearn.metrics.classification_report(y_true, y_pred, target_names = [str(i) for i in range(10)]))
print(f'Detailed Training Results of {MODEL_NAME_ANN} model')
y_true, y_pred = prep_y_true_pred(model_ANN, x_test.reshape(x_test.shape[0], -1), y_test)
conf_matrix_and_classification_report(y_true, y_pred)
print()
print(f'Detailed Training Results of {MODEL_NAME_CNN} model')
y_true, y_pred = prep_y_true_pred(model_CNN, x_test.reshape(x_test.shape[0], 28, 28, 1), y_test)
conf_matrix_and_classification_report(y_true, y_pred)
Detailed Training Results of ANN-784-64-64-10 model
0: [969 1 3 0 0 0 1 2 3 1]
1: [ 0 1129 1 1 0 0 1 0 3 0]
2: [ 1 0 1017 3 2 0 3 2 4 0]
3: [ 1 0 9 982 0 5 0 3 7 3]
4: [ 1 1 6 0 962 0 4 1 2 5]
5: [ 2 0 1 8 1 866 3 0 7 4]
6: [ 3 2 1 1 4 6 940 0 1 0]
7: [ 2 7 20 2 1 0 0 991 2 3]
8: [ 4 0 6 4 4 1 0 5 950 0]
9: [ 3 5 1 5 11 3 0 4 6 971]
-----------------------------------------------------
precision recall f1-score support
0 0.98 0.99 0.99 980
1 0.99 0.99 0.99 1135
2 0.95 0.99 0.97 1032
3 0.98 0.97 0.97 1010
4 0.98 0.98 0.98 982
5 0.98 0.97 0.98 892
6 0.99 0.98 0.98 958
7 0.98 0.96 0.97 1028
8 0.96 0.98 0.97 974
9 0.98 0.96 0.97 1009
accuracy 0.98 10000
macro avg 0.98 0.98 0.98 10000
weighted avg 0.98 0.98 0.98 10000
Detailed Training Results of CNN-LeNet5 model
0: [975 0 0 0 0 0 2 1 2 0]
1: [ 0 1128 1 2 0 0 1 1 2 0]
2: [ 0 1 1028 0 1 0 0 2 0 0]
3: [ 1 0 1 1003 0 2 0 0 3 0]
4: [ 0 0 0 0 974 0 3 0 1 4]
5: [ 1 0 0 3 0 885 1 0 2 0]
6: [ 2 3 0 0 2 2 949 0 0 0]
7: [ 0 1 4 0 0 0 0 1019 2 2]
8: [ 2 0 1 1 0 0 1 1 967 1]
9: [ 0 0 0 0 4 3 0 3 4 995]
-----------------------------------------------------
precision recall f1-score support
0 0.99 0.99 0.99 980
1 1.00 0.99 0.99 1135
2 0.99 1.00 0.99 1032
3 0.99 0.99 0.99 1010
4 0.99 0.99 0.99 982
5 0.99 0.99 0.99 892
6 0.99 0.99 0.99 958
7 0.99 0.99 0.99 1028
8 0.98 0.99 0.99 974
9 0.99 0.99 0.99 1009
accuracy 0.99 10000
macro avg 0.99 0.99 0.99 10000
weighted avg 0.99 0.99 0.99 10000
Modellərin test bazasındakı nəticələri:
"""
METHOD: Print evaluation results with metrics: LOSS - Categorical Crossentrophy, ACC, MSE, MAE
"""
def print_test_scores(model, x_test, y_test):
test_scores = model.evaluate(x_test, y_test, verbose=0)
for i in range(len(test_scores)):
metric_name = ''
if i == 0:
metric_name = 'Loss'
else:
metric_name = METRICS[i-1]
print(f'{metric_name}: {test_scores[i]}')
print('Test Scores - ANN\n--------------------------')
print_test_scores(model_ANN, x_test.reshape(x_test.shape[0], -1), y_test)
print()
print('Test Scores - CNN\n--------------------------')
print_test_scores(model_CNN, x_test.reshape(x_test.shape[0], 28, 28, 1), y_test)
Test Scores - ANN -------------------------- Loss: 0.11329323798418045 accuracy: 0.9776999950408936 mse: 0.003819412551820278 mae: 0.004927079193294048 Test Scores - CNN -------------------------- Loss: 0.034583061933517456 accuracy: 0.9922999739646912 mse: 0.0013603265397250652 mae: 0.0019016637234017253
7. Son qeydlər
Bilirəm ki, bütün üsulları və konsepsiyaları cəmisi bir məqalədə ifadə edə bilmədim. Amma məqsədim də o deyildi. Bu məqalənin məqsədi dərin öyrənmənin bir az daha dərindən anlaşılması üçün dayaq rolu olmasıdır, buna bir az da olsa, nail ola bilmişəmsə, mən də məqsədimə çatmışam.
Oxuduğunuz üçün təşəkkürlər!
8. İstinadlar
- Мустафаев Э.Э. Методы распознавания рукопечатных текстов. Баку, Издательство «Фуюзат», 2020, 189 стр.
- E.E.Mustafayev, R.B.Azimov. (2021). Comparative analysis of the application of multilayer and convolutional neural networks for recognition of handwritten letters of the Azerhttp://cctech.org.ua/index.php?option=com_content&view=article&id=281:abstract-21-3-6-arte&catid=13:vertikalnoe-menyu-en&Itemid=101baijani alphabet. Kiev. Cybernetics and Computer Technologies, No.3.
- Hands-On Machine Learning with Scikit-Learn, Keras and TensorFlow by Aurélien Géron (O’Reilly). Copyright 2019 Aurélien Géron, 978-1-492-03264-9.
- http://yann.lecun.com/exdb/mnist/
- Basheer, Imad & Hajmeer, M.N.. (2001). Artificial Neural Networks: Fundamentals, Computing, Design, and Application. Journal of microbiological methods. 43. 3-31. 10.1016/S0167-7012(00)00201-3.
- Cios, Krzysztof. (2018). Deep Neural Networks—A Brief History. 10.1007/978-3-319-67946-4_7.
- Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
- F. Rosenblatt, Principles of Neurodynamics, Cornell Aeronautıcal Laboratory, Inc., New York, 15 march 1961.
- Andina, Diego & Pham, D. & Andina, D. & Vega-Corona, Antonio & Seijas, Juan & Torres-Garcìa, J.. (2007). Neural Networks Historical Review. 10.1007/0-387-37452-3_2.
- Zhang, Jiawei. “Basic Neural Units of the Brain: Neurons, Synapses and Action Potential.” arXiv: Neurons and Cognition (2019).
- Sharma, Siddharth, S Sharma and Anidhya Athaiya. “ACTIVATION FUNCTIONS IN NEURAL NETWORKS.” (2020).
- Nwankpa, Chigozie, Winifred L. Ijomah, Anthony Gachagan and Stephen Marshall. “Activation Functions: Comparison of trends in Practice and Research for Deep Learning.” ArXiv abs/1811.03378 (2018).
- Ghosh, Anirudha & Sufian, A. & Sultana, Farhana & Chakrabarti, Amlan & De, Debashis. (2020). Fundamental Concepts of Convolutional Neural Network. 10.1007/978-3-030-32644-9_36.
- Gholamalinejad, Hossein & Khosravi, Hossein. (2020). Pooling Methods in Deep Neural Networks, a Review.
- Lee, Chen-Yu & Gallagher, Patrick & Tu, Zhuowen. (2015). Generalizing Pooling Functions in Convolutional Neural Networks: Mixed, Gated, and Tree.
- Y. Lecun, L. Bottou, Y. Bengio and P. Haffner, “Gradient-based learning applied to document recognition,” in Proceedings of the IEEE, vol. 86, no. 11, pp. 2278-2324, Nov. 1998, doi: 10.1109/5.726791.
- Yu, Dingjun & Wang, Hanli & Chen, Peiqiu & Wei, Zhihua. (2014). Mixed Pooling for Convolutional Neural Networks. 364-375. 10.1007/978-3-319-11740-9_34.
- Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. 2017. ImageNet classification with deep convolutional neural networks. Commun. ACM 60, 6 (June 2017), 84–90. DOI:https://doi.org/10.1145/3065386


